Your GPT acts like an intern. Here's how to make it think like you
Not longer prompts — your context. The four things to feed a GPT so it stops guessing and starts deciding the way you would.

01 — The problemWhy does a default GPT feel like an intern?
You ask for something specific and get something generic. Technically correct, vaguely useful, missing the point. Ask for "a welcome email to a new client" and you get "Hello! We're thrilled to have you on board and value your trust." Smooth. Faceless. Nothing a real person with a voice would write.
The model isn't broken — it's doing exactly what it was built to do: predict the most likely answer across everything it has seen. The most likely answer is the average one. And the average is what an intern produces: plausible, confident, and shallow.
An intern doesn't lack intelligence. They lack your context — who the work is for, what matters, where the traps are. Give an intern that context and they get sharp fast. A GPT is the same. The capability is already there; what's missing is your judgment.
02 — The shiftWhat does "putting your expertise into AI" actually mean?
People imagine it as a magic prompt. It isn't. Transferring expertise means making your invisible decisions explicit — the things you do automatically because you've done them a thousand times.
When you review a piece of work, you're running checks you never wrote down: is this on-brand, is the logic sound, would a client buy it, what's missing. The model can't see those checks. So you write them down once, and the GPT inherits them.
What happens when the foundation is skipped is easy to see in one case: someone configured an AI agent for five hours — it didn't work. Three more hours of tweaks — still wrong. The agent wasn't the problem. As he put it, the model can't think for you; your experience has to be digitized into it. You're not teaching it to be smart. You're teaching it to be smart your way.
03 — The foundationWhat does the "base" your GPT stands on actually consist of?
Before you feed a GPT, it helps to see what holds it up. Every working interaction with a model rests on four things:
- Task analysis. Knowing which tasks the model genuinely helps with and which are faster by hand. Skip this and you automate the wrong thing.
- Breaking work into micro-steps. A model runs on a clear algorithm, not a vague "do this." The process has to be laid out as sequential steps.
- Digitizing expertise. Handing over your method, criteria, and nuances. This is the part an intern never has.
- Prompt engineering. Choosing words so the output is a result, not filler.
Take the content agent everyone dreams of. The difference shows immediately:
You never handed over what "good" content must meet, which ideas to carry, which phrasings to use. Every output disappoints. You burn paid tokens on endless edits.
You handed over structure, voice, and quality criteria once. The agent nails it first time — no rework.
You can plug in the most elaborate agent there is. Without this foundation, you get an expensive toy that does nothing useful.
04 — The methodWhat four things should you feed your GPT?
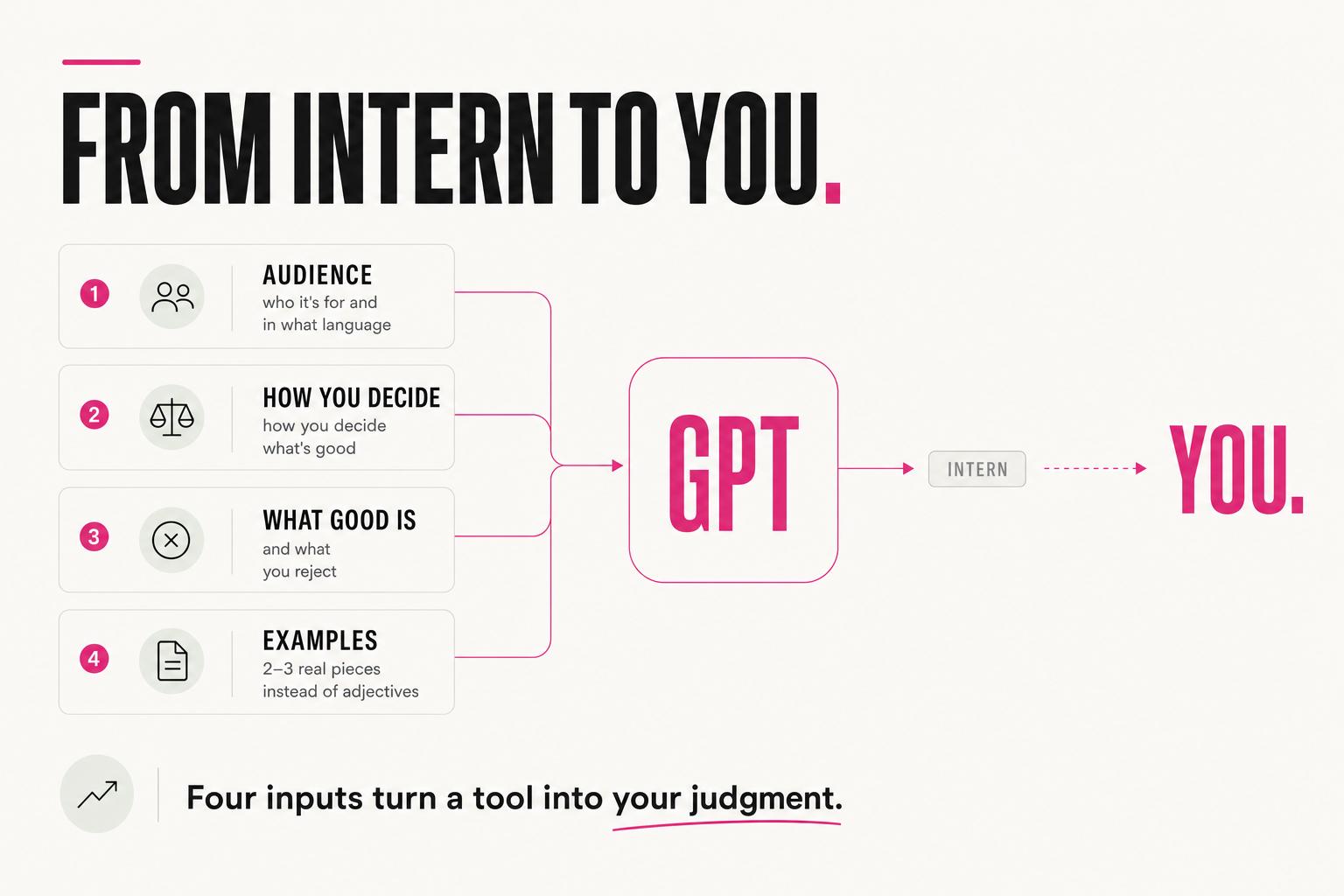
Almost all the leverage comes from four inputs. Give the GPT these and it stops averaging:
- Who it's for. The audience, their level, their language, what they already know. Without this the model writes for everyone, which is no one.
- How you decide. Your criteria — the questions you ask before you call something good. This is the part interns never have.
- What "good" looks like. Your standards, and just as important, what you reject. "Never do X" is as useful as "always do Y."
- Examples of your best work. Two or three real pieces beat a page of adjectives. The model learns your taste from samples, not from the word "professional."
AUDIENCE: practitioners who sell services; skeptical of hype.
GOOD = : 1 idea per paragraph; every claim has an example;
no buzzwords ("synergy", "innovative").
NEVER: open with "In today's world"; generalize without a number.
EXAMPLES: [attach 3 of your best pieces as files]You're not writing a better prompt. You're handing the model the context an intern would need to become a specialist: audience, criteria, standards, examples.
05 — StandardsWhy does "what NOT to do" matter more than it looks?
What turns an intern into a specialist isn't only the list of "do this" — it's the list of "never that." Constraints don't kill quality; they create it. At one conference an Amazon leader showed how experiments inside narrow, disciplined processes produced huge results precisely because the boundaries were clear.
An ethics example makes it concrete: psychologists can't hand an AI full transcripts of client sessions. But they can use the model to draft personal assignments from their notes, or optimize parts of a session from short excerpts. The boundary doesn't kill the value — it carves a safe channel where the AI still drives a result.
Port this into your GPT's instructions literally: what it may never do, which data not to surface, which phrasings are banned. A five-line never-do list often moves the output more than a paragraph of praise.
06 — Your edgeWhy is your context a competitive advantage?
Because every general model — OpenAI, Claude, the rest — ships with basically the same data and the same default approaches. If everyone is prompting the same models, the prompt can't be your edge. Your data can.
Simple example: anyone can say "write me an ad headline." But if you have the results of hundreds of campaigns, analyzed for what worked and what didn't, the model's answer becomes a completely different, far more precise thing. Same engine; your context creates a giant difference.
The scale of that difference isn't theoretical anymore. At the same conference one speaker described standing up 6,000 internal agents, heading for 10,000 by year-end, with 60 different models available to staff. Now picture their competitor — still banning AI because they never sorted out data security. The market gap is enormous: either this is your advantage now, or you're ten steps behind.
07 — In practiceHow do you build it without coding — and not feed it every time?
Use a Custom GPT or a project workspace — anywhere you can save instructions and attach files. Put the four inputs in as the standing instructions, and attach your example work as files the model reads every time.
Then do the one step most people skip: correct it. When it gets something wrong, don't just fix the output — add the rule that would have prevented it.
It: opened a post with "In today's AI-driven world..."
You: (fix the output) + add to the instructions:
"NEVER open with an abstraction. First line = a concrete fact or scene."
→ next time it doesn't.Each correction makes the GPT a little more like you. After a few rounds you stop prompting from scratch and start delegating to something that already knows how you think. That's the real promise: not a faster intern, but a second version of your judgment that runs without you in the room.
FAQ
Isn't this just a long prompt?
No. A prompt is a one-off request; this is standing context plus example files the model uses every time. The point isn't length — it's giving the model your audience, criteria, standards and taste so it doesn't fall back on the average.
How many examples do I need?
Two or three strong, real pieces are usually enough. The model learns taste from samples far better than from descriptions. Add more only if your work spans clearly different formats.
Will it really sound like me?
It gets close fast if you feed it real examples and correct it when it drifts. The voice comes from your samples; the judgment comes from your criteria. Both improve every time you fix an output instead of just accepting it.
What about data security — what shouldn't I put in a GPT?
Anything client-sensitive you wouldn't trust to a third-party service. A good move is to avoid raw data wholesale — work from excerpts, or have it draft assignments off your notes. The boundary doesn't kill the value: it carves a safe channel, like psychologists using session snippets instead of full transcripts.


